There are several different settings available that help you control the way an agent runs in the Web Console. This article outlines those settings, when they’re useful, and what they do.
Open an agent’s error handling settings
In the Web Console:
-
Open an agent.
-
Select the
 to open the configurations menu.
to open the configurations menu.
- Select
 Harvesting.
Harvesting.
- Select Error Handling.
Error Handling
The error handling settings give you control over how the agent responds to an error. There are two types of errors that an agent may encounter.
Agent error
An agent error occurs when the agent encounters something it didn’t expect, or could not find an object on the webpage. These errors can be ignored using the settings in this window or handled by making changes to the agent itself (recommended).
Website error
A website error happens when the website that the agent targets is unavailable, or the webpage itself has returned an HTTP error. These are often one-off events that can be resolved by resuming the agent job.
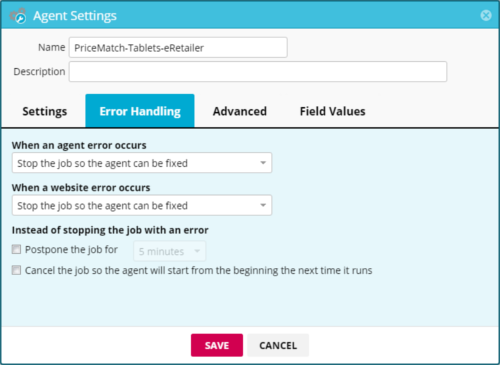
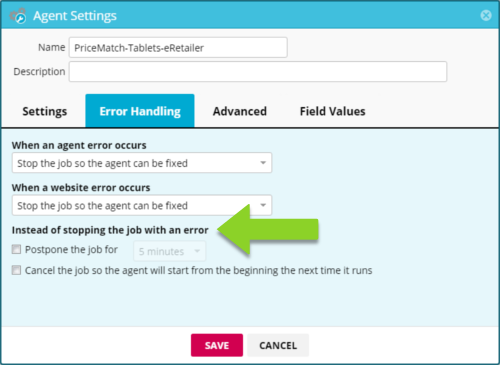
When an agent error occurs
Attempt to ignore the error and continue
Use this setting if the agent will regularly encounter common error types (such as “Element not found”) and this is a known and acceptable behavior.
For example, you might want to use this setting if you’re scraping a large number of records and would rather lose occasional records than intervene manually every time an item is not found.
Do not use this setting until you have fully tested and refined the agent, making sure it is generally free of errors.
Stop the job so the agent can be fixed
Use this setting if you do not expect the agent to encounter an error and accuracy is a high priority. The agent will pause when it encounters an error, allowing you to modify the agent so that the error will no longer occur, and resume the agent where it left off.
This setting can also be used if you plan to postpone or cancel the job when an error occurs by adjusting the settings in the Instead of stopping the job with an error section.
When a website error occurs
Let the system decide what to do
The system may or may not stop the job with an error, depending on the type and persistence of the error, such as navigation errors, or text that cannot be found after multiple attempts. This is the default setting.
Ignore the error and continue
Use this setting if the website frequently returns HTTP errors, but you have found that errors from that website do not necessarily make the data inaccessible or do not indicate an issue that can be remedied by better agent design.
For example, some websites return an HTTP error if a search returns no results. In this case, the agent should be designed to account for this fact and move on. It should not stop running or return an error.
Do not use this setting until you have fully tested and refined the agent, making sure it is generally free of errors.
Stop the job so the agent can be fixed
Use this setting if you anticipate that any website errors that occur (such as HTTP errors) were caused by the way the agent runs (such as moving from page to page too quickly) and can be resolved by modifying the agent.
Instead of stopping the job with an error
This setting will apply to either of the drop-down menus above that are set to Stop the job so the agent can be fixed. If enabled, this setting provides alternatives to stopping the job.
Postpone the job for __ minutes
Use this setting if resuming this agent after encountering an error has been an effective solution in the past, as this automates that process. Increase the number of minutes if you suspect that the website might catch the agent (generally not necessary if the agent uses premium harvesting).
Cancel the job so the agent will start from the beginning the next time it runs
Use this setting if you no longer need data that would appear after an error has occurred.